

Эта история создана на основе опыта организаций и предприятий в России, которые сегодня стоят на перепутье развития своей ИТ-инфраструктуры: идти в облака или оставаться на своей площадке? Переходить на оплату ресурсов как услуги или продолжать покупать их как товар? Сначала ИТ-ресурсы для развития бизнеса или сначала развитие бизнеса для оплаты ИТ-ресурсов? Компания HPE предлагает не выбирать, а взять лучшее от двух миров. Конечно, найти реальную компанию, в которой одновременно и в такие сжатые сроки происходили бы все описанные в этой истории события, непросто. Но надеемся, что каждый читатель найдет в ней что-то близкое лично для себя.
Ранним предновогодним утром парковку за окном заносит снегом. Желтые мигалки дорожной техники выглядят, как сигнал тревоги. С самого утра Павла не покидает ощущение, что он зря уезжал на прошлой неделе. Говорят, что качество своей работы можно проверить по последствиям похода в отпуск: если твое отсутствие ни на что не повлияло, значит, ты все делаешь как надо. Но в этот раз не так. «Надо было потерпеть до праздников, — подумал Павел, — а теперь и на праздниках придется поработать».
Всего за неделю в логистической компании «Экспресс Трек» (ЭТ), в которую этим летом на должность директора по ИТ вышел Павел, случилась долгожданная революция. Под давлением инвесторов совет директоров принял три решения, которые напрямую завязаны на работу отдела ИТ:
- Выйти еще в пять регионов России и Казахстана с подключением 200 своих и партнерских пунктов выдачи заказов и открытием двух новых сортировочных центров для дальнейшего расширения;
- Подписать договор с российским производителем одежды «Wool» на дистрибуцию и поддержку продаж их товаров через собственные каналы ЭТ в Юго-Восточной Азии;
- Разморозить проект супер-приложения со встроенным маркетплейсом и автоматическим клиентским сервисом.
Задачи для отдела ИТ:
- Полная готовность инфраструктуры для новых регионов максимум за 4 месяца (привет, новый KPI для годового бонуса всей ИТ-команды);
- Гарантия высокой доступности сервисов для Wool;
- Ускорение запуска, а потом и доработки маркетплейса. Павла заочно включили в рабочую группу и, если читать между строк, возложили на него ответственность за сроки и качество, по крайней мере, на старте.
Финансирование инвестиций в ИТ — по обоснованию.
Именно ради этих инициатив Павел пришел в Экспресс Трек, и с нетерпением ждал их начала. Но недели шли, решения откладывались, а рутина постепенно отняла все время. И что-то подсказывает Павлу, что эти три проекта вынесут на поверхность все узкие места в процессах и инфраструктуре ИТ, которые он уже успел обнаружить. Павел отключает телефон, закрывает ноутбук и берет лист бумаги и ручку. «Так, — настраивает он себя, — разобьем на части».
Три проекта
«С первым пунктом особых проблем нет: расширение присутствия идет уже 10 лет, за это время требования к оборудованию и ПО для складов сведены в стандарт, — размышлял Павел. — Считаем, что три месяца уйдут на закупку и доставку, но потом отправим пару опытных ребят на наладку, к сроку управимся. Тревожит, что число складов перевалит за десяток, и везде зоопарк с оборудованием. У администраторов уже вся грудь в орденах за сертификацию от разных вендоров, и все равно не каждый уверенно разбирается во всем спектре. Но дальше интереснее.
У ЭТ нет своей ИТ-инфраструктуры в Таиланде и Малайзии, ключевых новых рынках для Wool. На перевозках и дистрибуции в этой части света ЭТ съела стаю собак, но в части ИТ для своих нужд пока обходилась минимальным набором сервисов, размещенных в арендованных в сингапурском регионе AWS виртуальных машинах, поближе к пользователям. Это создало отдельный «остров» в инфраструктуре и увязкой управления им в общие ИТ-процессы никто еще не занимался. Оценкой затрат на масштабирование — тоже. А масштабировать придется, ведь кроме классической дистрибуции договор с Wool включает в себя решения для поддержки канала продаж «под ключ». Облачные виртуалки нужно будет резервировать и бэкапить, иначе не может идти и речи об SLA по доступности. А может все-таки развернуть свою инфраструктуру на месте? Как ей управлять и как поддерживать, и что делать с уже развернутыми виртуалками? Вопрос открытый.
И, наконец, проект с маркетплейсом. В нем ЭТ будет предлагать продавцам товаров свои склады, логистику и, главное, дешевый трафик. Решено минимизировать бюджет на рекламу, а качество сервиса довести до совершенства, чтобы пользователи оставались и звали знакомых. Еще вчера это все казалось фантастикой, а сегодня — очевидная необходимость, чтобы загрузить свои мощности по складам и перевозкам на высококонкурентном рынке. В этом проекте понятно: формируем буферный резерв ресурсов для группы разработки и отдаем как минимум одного дежурного администратора-универсала в режиме 24/7 им в команду. По инфраструктуре больше всего неопределенности с системами хранения. Сейчас разработка сидит на каком попало железе, а тестировать маркетплейс они хотят на чем-то близком по времени отклика к продуктиву. Но не сказать, чтобы на продуктиве у нас было много места. Да и гарантировать быстрый отклик, когда сбоку подпирает Oracle логистов с высшим приоритетом обслуживания, это шаг отважный. Новая хранилка, однозначно. Много места на первое время не потребуется, но «железка» должна быть действительно быстрой.»
От предпосылок к вариантам решения
«Итого, — продолжает размышлять Павел, — распишем узкие места, риски и открытые вопросы».
1. Региональные сортировочные центры:
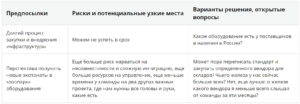
Павел звонит ведущему администратору, и уже через пару минут находит ответы на свои вопросы. Он, наконец, чувствует, что мысли образовали поток и понеслись к решению.
«Хорошо, — он снова берет ручку и бумагу, — начнем с такой гипотезы: если на новые склады мы закупим серверы HPE ProLiant, системы хранения HPE MSA, и сеть — тоже от HPE, мы получим практически беспроблемную инфраструктуру, которой мы гарантированно можем управлять из центра и только изредка трогать руками. Поставки со складов в России, здесь сэкономим пару месяцев. Установку и замену сбойных компонентов в регионах сделает вендор, по прошлому опыту их инженеры ездили на площадки и не в такие места. Рабочие места сделает партнер-интегратор. Наши ребята поедут только на 3-4 дня разлить софт. Итого 4 месяца выглядят очень реалистично, только бы площадки были физически готовы. С этим разобрались, смотрим дальше».
2. Поддержка сервисов с гарантированным SLA
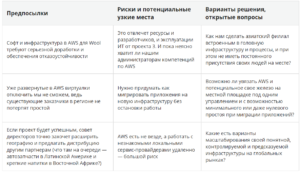
Еще один звонок, на этот раз — директору одного из системных интеграторов Олегу. Павел доверяет ему самые интересные проекты вот уже несколько лет. Олег говорит: «Как ты вовремя позвонил! Мы только что развернули у себя в лабе HPE Nimble. Это система хранения, она умеет прямо из коробки реплицировать тома в AWS, там их можно презентовать виртуалкам, а потом синхронизировать обратно с локальной СХД. Это называется Cloud Volumes. У HPE есть для таких миграций средства и посерьезнее, например, Zerto. HPE дает на Nimble гарантию доступности 99,9999% и говорит, что большинство заказчиков вообще никогда не видели на ней простоев. Управляется полностью удаленно, даже проще их MSA. Умный мониторинг InfoSight находит и даже предсказывает проблемы от уровня отдельных частей железа до приложений. У вас с SQL были какие-то непонятные задержки, да? Вот она и внутрь SQL может посмотреть. По производительности у Nimble все достойно, — продолжает Олег. — На практике проблем не замечали. А еще недавно появилось новое поколение — теперь называется Alletra 6000. Оно заметно быстрее, проще масштабируется по емкости, и еще у него есть консоль управления Data Services Cloud Console, она же DSCC».
«Так, Олег, я все понял, — перебивает Павел. — Уговорил. Объем нашего «острова» в Азии ты знаешь. Помножь на два и посчитай этот Nimble или Alletra, как хочешь. С серверами и сетью. И положи туда поддержку с гарантированным временем восстановления. Да, я знаю что вы не против в Сингапур слетать с диском в чемодане, но лучше, пожалуйста, посчитай вендорскую поддержку на месте. А на инсталляцию можете вы поехать, вы сертифицированы? Нет, мне не нужен «любой дурак», мне вы нужны. Ну хорошо, что вы можете. А про эту Cloud Console потом поговорим».
«Что ж, тут вроде бы направление тоже понятно, — подытоживает Павел. — Хорошо, что тоже HPE: меньше учиться, да и поддержка у них без вариантов самая лучшая, проверял не раз. А теперь — самое интересное».
3. Маркетплейс:
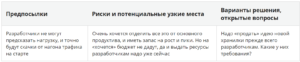
Звонок Сергею, главе группы разработчиков. Сергея год назад переманили из одного из интернет-гигантов, где он как раз строил маркетплейсом и суперприложение. Времени в ЭТ он, как оказалось, не терял.
«Итак, — конспектирует разговор Павел, — до того, как проект заморозили, вся инфраструктура у разработчиков уже была выстроена на AWS. Они к этому привыкли, и уходить не хотят. Захотели развернуть еще один инстанс, через минуту ресурсы уже готовы, разливают образ, и вперед. Договорились, что они продолжают работать в облаке, а мы пока готовим для них полосу для приземления всего их хозяйства к нам в периметр».
Сергей, как показалось Павлу, не убежден, что им так уж надо переезжать. Говорит, что веерные отключения амазоновских адресов прекратились, так что и для России маркетплейс в AWS работать будет нормально. Неплохо бы посчитать и сравнить стоимость ресурсов там и здесь, с перспективой на рост, чтобы рассуждать в деньгах. Но то, что разработчики в облаке, даже хорошо, потому что все их потребление учтено. Как образмерить локальную инфраструктуру на замену понятно.
«Еще договорились, — продолжает записывать Павел, — полностью разделить нынешние продуктивные приложения с маркетплейсом. У разработки весь проект на микросервисах, так что они готовы «высадиться» куда угодно. Итого требуемую емкость для начала определили как 30 ТБ. Микросервисы будут генерировать очень разнообразную нагрузку, нужно уметь ее приоритезировать по времени отклика, и желательно автоматически. И масштабировать ресурсы инфраструктура должна уметь сама по сигналу от скрипта, который плодит и гасит инстансы микросервисов вслед за ростом и падением нагрузки. То есть у железа должны быть понятные и стабильные API. И точно нужно, чтобы с первых дней маркетплейс поражал пользователей скоростью, «чтобы сразу разницу почувствовали и остались у нас». Для этого хранилка должна даже на начальных объемах показывать все, что может».
Взять лучшее от двух миров
«А все-таки, как оставить часть разработки в облаке, но чтобы эксплуатация при этом не запуталась и не закопалась в своем и облачном? — размышлял Павел. — Что там Олег говорил про облачную консоль?»
Еще один звонок Олегу. Он уже собрал спецификацию на HPE Alletra 6000 и серверы. Сумма внушительная, но Олег говорит, что может это все установить в ЭТ вообще без предоплаты. «А там уже сколько ресурсов потребите, за столько и заплатите, как в облаке. У HPE такая модель «все-как-сервис» называется GreenLake. Сергею вашему понравится, да и ценник по сравнению с AWS его не удивит». На вопрос «В чем подвох?» Олег ответил: «Для тебя — ни в чем. Да, в GreenLake обязательно входит комплексная поддержка на всю инфраструктуру. Но ты же сам на поддержке экономить не хочешь, у тебя KPI про возможности для роста бизнеса, а не про экономию и не про развитие компетенций команды. А когда покажем экономику вашим финансам и инвесторам, когда они поймут, что деньги в обороте вообще не нужно морозить — сам увидишь их реакцию».
Но: обратно к хранилищу для маркетплейса. Олег говорит: «У HPE есть еще Alletra 9000. Огонь, а не машина. 200 микросекунд задержки — норма, быстрая сразу с минимальной емкости. Репликацию в облако и обратно тоже умеет. Та самая Data Services Cloud Console (DSCC) — это средство управления, глобальная админка. Поддерживает сейчас Alletra 6000, Alletra 9000 и Primera, а скоро будет поддерживать Nimble и другие продукты HPE. Общее впечатление от управления средой в DSCC — как в облаке, даже лучше. Получается, у вас и оплата будет по облачной модели через GreenLake, и управление тоже — через DSCC. Для биллинга есть приложение GreenLake Central, умеет тарифицировать ресурсы и в облаках, и у себя на площадке, по заданным ценникам за единицу ресурса. Это к вопросу как сравнить, что выгоднее. Еще есть прикладные сервисы внутри DSCC: например, разделение прав доступа с многофакторной аутентификацией, выделение оптимальных ресурсов под задачу в пару кликов или через API. Есть бэкап в облако, а скоро научатся бэкапить и AWS EC2-инстансы. И это все по понятной подписке, дешевле, чем в AWS, и без скрытых затрат».
Звучит, как будто эту систему специально делали для Сергея.
«Подожди, так «облачная консоль» — это значит, что нашей инфраструктурой для важнейших проектов мы будем управлять из облака? Где хостится эта консоль, на том же AWS? «А можно ее перенести на свою площадку?», — спрашивает Павел.
«Пока нет, но это обещают на следующий год, — говорит Олег. — А пока вы и так в облаках».
Итог
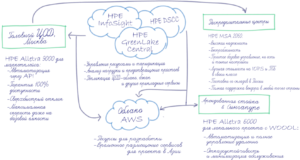
«Хорошо, — Павел подытоживает свои наброски, — нарисуем ИТ-архитектуру для Экспресс Трек»,
- В региональных распределительных центрах инфраструктура на базе HPE ProLiant и HPE MSA работает почти без участия человека, новые системы и апгрейды поставляются быстро со складов в России, поддержка вендора закрывает рутинное обслуживание
- На удаленных зарубежных площадках стоит HPE Alletra 6000 — автономная система хранения, управляемая из облака и интегрированная с публичном облаком
- Для требовательных приложений в составе маркетплейса используется HPE Alletra 9000 — она хорошо переваривает разнообразные нагрузки, показывает очень быстрый отклик на чтение и запись и имеет гарантию 100% доступности от вендора
- Своя инфраструктура управляется единообразно из HPE DSCC, как облако
- Сервис HPE InfoSight следит за состоянием всей экосистемы от железа до приложений
- Приложения могут ездить в облако и обратно на свои площадки благодаря внутренним средствам систем хранения и HPE Cloud Volumes, или софту HPE Zerto.
- Все ресурсы, облачные и локальные, учтены в GreenLake Central, их стоимость с оплатой по мере потребления через HPE GreenLake понятна внутренним владельцам проектов и приятна финансистам
- По большому счету, все работает само, а ИТ-команда занимается не инфраструктурой, а задачами для бизнеса
«Выглядит красиво, — гонит от себя лишнюю скромность Павел, — а старт с нулевыми вложениями и оплата четко по мере роста в дальнейшем точно помогут в обосновании инвестиций».
Хорошо, что скоро праздники, и можно будет над этим еще поработать, не отвлекаясь на рутину!
P.S. Все совпадения с реальными лицами и событиями просим считать неслучайными. Спасибо всем, кто явно или косвенно повлиял на эту статью!
Конец. Или только начало?
Смотрите запись вебинара об HPE Alletra и приходите на новые вебинары HPE, чтобы узнать больше!
И уделите 5 минут на опрос по управлению своей инфраструктурой в облачном стиле, пожалуйста.
И еще, с наступившим Новым интересным годом!


