

Защита данных на всем протяжении их существования – от возникновения до помещения в архив – является непреложным обстоятельством сохранения интеллектуальной и конфиденциальной информации от компрометации или кражи. В статье рассмотрены основные методические принципы защиты информации на всех этапах ее обработки.
Александр Васильевич Зубарев, кандидат технических наук, старший научный сотрудник, директор по информационной безопасности ООО «Техкомпания Хуавэй»
zubarev.alexander@huawei.com
Михаил Николаевич Шпак, начальник отдела технологического консалтинга Huawei Enterprise ООО «Техкомпания Хуавэй»
Shpak.Mikhail1@huawei.com
Ценность данных
Каждая организация отличается по формату ведения деловой деятельности, индустрии работы или формы собственности, но переоценить значимость данных в наше время практически невозможно. Информация правит миром, и злоумышленники очень изобретательны, а иногда, скажем прямо, настолько зловеще талантливы, что можно провести прямую аналогию с профессором Мориарти из бессмертного произведения А. Конан Дойла или сослаться на рис 1.

Перед тем как защищать данные, следует определиться, какие именно из них для нас важны и как их следует классифицировать для построения необходимого уровня сквозной
защиты.
Рассмотренные ниже классификации не претендуют на оригинальность и полноту, но обеспечивают понятную парадигму ценности данных и, следовательно, риска их нарушения.
1) Низкий уровень риска.
Информация из этой категории не предназначена для публичного использования, но если бы она была скомпрометирована, то влияние этого факта на организацию было бы
очень незначительным, например:
- общедоступные «белые» IP-адреса серверов;
- логи приложений без признаков персональных данных или коммерческих секретов;
- перечень коммерческого и/или открытого ПО, используемого в компании.
2) Умеренный уровень риска.
Эта информация категории NDA (Non Disclosure Agreement) не должна разглашаться за пределами организации иначе как в соответствии с положениями действующих в ней документов о неразглашении. Во многих случаях (особенно в крупных организациях) этот тип данных должен раскрываться только по мере необходимости внутри организации и только определенным категориям сотрудников. Вот несколько примеров:
● подробная информация о том, как устроены информационные системы компании, их архитектурные блоки, карты взаимодействия сервисов, а также потенциальные узкие места в ИКТ-ландшафте, то есть все то, что может облегчить злоумышленнику подготовку атаки;
● информация о персонале, которая может предоставить злоумышленникам почву для применения фишинга или методов социальной инженерии (этот канал до сих пор является одним из наиболее уязвимым для утечки или компрометации данных);
● обычная финансовая информация, такая как покупки или возмещение расходов на командировки, которая может быть использована для косвенных выводов о деятельности компании.
3. Высокий уровень риска
Эта информация жизненно важна для компании, и ее разглашение может нанести значительный ущерб или вовсе привести к ликвидации организации. Многие помнят грустную историю компании Nortel, связанную с недостаточно бережным отношением к сохранению коммерческой тайны. Доступ к этим данным должен очень строго контролироваться с использованием множества мер физической и информационной безопасности. Вот несколько примеров такой информации:
- подробная информация о будущей стратегии компании или финансовая информация, которая в случае хищения обеспечила бы конкурентам значительное преимущество;
- коммерческие секреты, например, такие как дизайн-процесс популярного мобильного телефона 5G или высокопроизводительной системы хранения данных;
- секреты, которые предоставляют «кольцо всевластия», такие как учетные данные для полного доступа к ИКТ-инфраструктуре;
- конфиденциальная информация, переданная на хранение: например, финансовые данные клиентов;
- любая другая информация, случаи нарушения которой могут найти отражение в прессе.
Теперь, когда мы определились с предложенной классификацией информации, возникает вопрос: когда и как стоит ее защищать?
Сразу же отбрасываем идею установки песконасыпного сейфа в 1 тонну весом или использование классического варианта вида Форт Нокс, которые в информационную эру не работают.
Другое экстремальное решение – формальная информационная безопасность, которая может спасти только при проведении проверки регулятором.
Конечно, искушенные читатели вспомнят про эшелонированную защиту на разных элементах инфраструктуры: сети, серверы, виртуализация и возможные периметры безопасности А, Б, В, Г и Д из локальной классификации регуляторов.
Такой подход, конечно, имеет право на жизнь, но он не отражает реалий жизненного цикла разных данных в информационной системе, их замешивание, совместное использование, размытие критериев и т. п., что вполне возможно в будущем. Или в какой-то момент уровень ценности данных может вырасти, а методы их защиты останутся прежними.
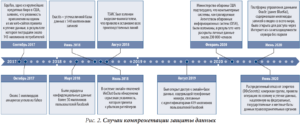
Перед тем как перейти к методическим принципам защиты стоит напомнить о самых ярких случаях фиаско при их нарушении (рис. 2).
Восемь основных принципов сквозной защиты информации
Методологически защиту информации стоит рассматривать комплексно, исходя из ее жизненного цикла: от момента возникновения до прекращения обработки устаревших данных.
Принцип № 1 – интуитивно понятная защита данных, в рамках которой весь жизненный цикл данных прозрачен и контролируем для компании, схематично отображен на рис. 3.

Этот принцип предполагает, что жизненный цикл имеет следующие четыре категории признаков:
1) неизменяемый и отслеживаемый – предотвращает утечки данных с помощью внедрения видимых и невидимых водяных знаков в документы и имитовставки водяных знаков
в базы данных;
2) прозрачный и определяемый – защита жизненного цикла данных с учетом идентификации большого количества типов персональных данных и форматов файлов;
3) безопасный и надежный – контроль доступа и защиты пользовательских данных без деградации качества продуктивных служб;
4) общий и гибкий – с возможностями автоматизации через API-интерфейсы для клиентов и разработчиков с целью автоматизации возможностей защиты данных.
Благодаря этим признакам можно сформулировать Принцип № 2 – безопасность сбора данных.
И тут надо решить дилемму: как идентифицировать персональные данные из сотен миллионов файлов и как быстро идентифицировать конфиденциальные данные в БД объемом в сотни терабайт?
Здесь на помощь приходят четыре инструмента классификации критичной информации:
- иерархичность уровней механизмов идентификации данных;
- правила соответствия по умолчанию;
- обработка естественного языка NLP;
- сравнение файлов по признакам.
Все эти инструменты гибко связаны друг с другом, и их можно использовать как в классической инфраструктуре ЦОДа, так и в современном DevOps-цикле в облачной инфраструктуре.
По мнению Gartner, «для эффективной идентификации данных может потребоваться система управления безопасностью данных», вот только стадия «может» переходит в стадию «обязательно нужна».
В итоге мы получаем такие сквозные возможности в нашем ландшафте, как:
- автоматизация идентификации конфиденциальных и персональных данных;
- поддержка индивидуальных правил идентификации в соответствии с различными бизнес-требованиями;
- оптимизация структуры файлов для точной идентификации конфиденциальных данных;
- получение интуитивно понятных отчетов о соблюдении требований.
Принцип № 3 – это безопасность передачи данных, и здесь нас, прежде всего, интересует строгая аутентификация и шифрование «в один клик» для пользователей, терминалов, кампусов и ЦОДов. Все взаимодействие по открытым каналам должно быть строго контролируемым и аутентифицированным. Наши офицеры сетевых служб и офицеры информационной безопасности должны в любой момент времени быть готовы ответить на вопросы:
- как подтвердить личность или сущность?
- как построить безопасный канал передачи данных с пользователями?
- как соответствовать требованиям законодательства на техническом уровне?
Для пользователя важны следующие аспекты:
- является ли страница web-сайта настоящей?
- URL-адрес указывает на принадлежность web-сайта компании ХХ, но можно ли доверять этому?
- будут ли украдены отправленные имя пользователя и пароль?
И инструменты, лежащие в основе принципа, как раз обеспечивают безопасную передачу данных между облаком и локальными ЦОДами, а также аутентификацию источника данных и шифрование передачи данных на уровне приложений.
Принцип № 4 – безопасность хранения данных предусматривает использование ключей шифрования данных (DEK), мастер-ключей заказчика (CMK) и корневых сертификатов, отображенных на рис. 4, и позволяет реализовать эшелонированный вариант шифрования данных для разных сервисов.
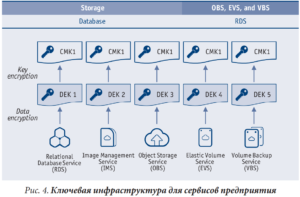
Вложенные процедуры шифрования помогут нам обеспечить:
- поддержку шифрования данных, самостоятельно импортированных ключей и ключей службы хранения;
- безопасность хранения данных, включая шифрование конфиденциальных данных, данных финансовых платежей и файлов видеонаблюдения.
Явными плюсами такого подхода будут более безопасное хранение и обработка данных, а ключевая система позволит контролировать несколькими связками ключей большое количество сервисов, а также следить за составом и жизненным циклом ключевой инфраструктуры, например, за обязательной ежемесячной ротацией ключей.
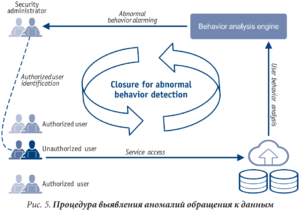
Посредством Принципа № 5 – безопасность использования данных можно проанализировать уровни безопасности данных, а также определить аномалии поведения пользователей при работе с данными.
Визуально мы получаем следующий формат работы:
- интеллектуальная идентификация аномалий (представлена на рис. 5):
— встроенные модели алгоритмов машинного и глубокого обучения могут использоваться для идентификации аномалий на основе поведения пользователей; - многомерный анализ: анализируются источники доступа, объекты и учетные записи;
- обработка аномальных событий:
— угрозы безопасности постоянно отслеживаются и устраняются.
Водяные знаки данных как Принцип № 6 помогут установить и отследить потребителя данных в инспектируемый момент времени.
В настоящее время, например, очень популярно хищение данных посредством их фотографирования или записи с последующей публикацией, например, в Telegram-каналах или продажей в DarkNet.
Возможны следующие сценарии реализации указанного принципа:
- уведомление об авторских правах или корпоративной ответственности: водяной знак может помочь владельцам данных защитить свои законные права и точно отследить канал утечки;
- автоматизированный мониторинг:
— водяной знак может помочь владельцам отслеживать копирование и распространение цифровых знаний.
Вариант реализации инъекции водяных знаков в документы представлен на рис. 6.

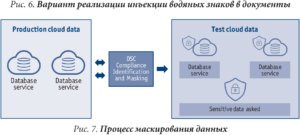
С помощью Принципа № 7 – маскирование конфиденциальных и критических данных можно провести требуемые манипуляции для обезличивания критических данных при работе с субподрядчиками и аналитиками.
К примеру, если внутри компании обрабатываются данные о геологоразведке, их нельзя передавать куда-либо вовне без дополнительного обезличивания и/или рандомизирования для предотвращения риска утечки данных через третьих лиц или их компрометации таковыми. Или при испытаниях технологии Больших данных нельзя передавать
реальную финансовую информацию заказчиков компании, но применение обезличивания и маскирования (рис. 7) позволяет найти дополнительные сценарии использования накопленных данных.
Соответственно, вручную проводить такие операции не только затратно с точки зрения временных ресурсов, но и небезопасно в плане возможных ошибок, в том числе существенных, на этом пути, учитывая человеческий фактор.
На уровне Центра безопасности данных (Data Secutity Center – DSC) реализуются следующие инициативы:
- поддержка всех сценариев в ЦОДе и в облаке: DSC должен работать и с распространенными сервисами данных, и с самописными БД и приложениями;
- обеспечение разнообразных сценариев маскирования:
● DSC должен использовать несколько алгоритмов для правильного
маскирования данных в различных форматах;
● DSC должен маскировать или искажать конфиденциальные данные, чтобы они не отображались
в виде обычного текста; - поддержка соответствия требованиям с простыми и ясными процедурами: DSC должен автоматически предоставлять рекомендации по маскировке данных и позволять пользователям настраивать правила маскировки всего за несколько кликов или выполняемых процедур.
Последним по очереди, но не по значимости, является Принцип № 8 – безопасность уничтожения данных.
Если не так давно для уничтожения цифровых или бумажных носителей нужно было задействовать трех сотрудников и одну специальную печь, а также потратить на это некоторое время, то нынешние подходы уже не выглядят столь радикально, тем более применительно к современным платформам.
Модель потребления сервиса в таком ключе, как она представлена в правой части инфографики на рис. 8, как раз предполагает удаление с физического носителя данных по истечении их жизненного цикла проверенным методом (к примеру, подобный механизм используется в облаке Huawei Cloud), а не простым удалением логических ссылок на физическом носителе.

Заключение
В современную эпоху методики, принципы и практики безопасного использования данных в полном их жизненном цикле предполагают, прежде всего, зрелость компании, а также совместную и скоординированную работу всех ее подразделений, включая ИТ- и ИБ-службы. Четкие внутренние критерии разделения слоев данных и работы с ними помогут выстроить более прогрессивную и кумулятивную политику их защиты.
Предложенные в статье методические принципы могут быть использованы любыми организациями для построения системы сквозной защиты информации в качестве прочного и надежного фундамента успешного и устойчивого развития в условиях цифрового настоящего.
Журнал «Защита информации. INSIDE» № 6’2021


